目次
- multi-armed bandit導入
- epsilon-greedy
- UCB
- 実験結果
- 終わりに
導入
bandit問題をご存知ですか?私は知っています…とここで引用を貼りたかったのですが、良い感じのが無かったので書きます。
これは簡略的な定義であり、bandit問題はそれ単体が一分野をなす問題のようです。良ければこちらを参照してください。バンディット問題の理論とアルゴリズム (機械学習プロフェッショナルシリーズ)
プレイヤーは各slotの情報を持っていない事が重要です。scoreを最大化するためには各slotを試し、その性能を推定する事が必要になります。これを探索と呼びます。
また、推定結果を利用して高いscoreを得ることが不可欠です。これを活用と呼びます。
探索と活用、というワードは強化学習によく出てきます。良い感じにバランスを取るとより高い性能が出るためです。
本問題はそれを例示するためのtoy problemとしても良いのですが、問題設定の素直さから、応用にも使えます。
やや気が早いですが、応用例としてゲームAIを考えてます。プレイヤー的には、どの手が良く、どの手が悪いか推定する必要があります。が、思考リソースは有限です。似た構造をしているとわかるでしょう。
導入なので、適当なヒューリスティックでも述べておきます。
それなりに良い気もしますが、もっとちゃんと考えようというモチベーションがあります。
epsilon-greedy
調べれば出てきます
UCB
epsilon-greedyでは、得られた値の平均値を期待値の推定値としていました。そのうえで、一定確率でランダムな行動を取ることで探索のバランスを取っていました。
ここで、信頼区間の考えを導入します。信頼区間が広いほど「今後の探索によって現在の推定値から大きく変わる」可能性が高いわけです。なので、信頼区間の広さを選択に組み込むことで、パラメータレスな探索が組めそうです。
よって、次のアルゴリズムを考えます。
信頼区間の構成の為に、確率的な振る舞いを解析する必要があります。
Hoeffding's inequality という汎用性の高い不等式があるので、それを用いると良いです。こちらを参照してください。 なお、分布が予測できる(例えば正規分布など)場合はよりタイトな推定が可能でしょう。
確率評価が出来るので、あとは信頼区間の幅をどう選ぶのかを決めます。例えば 99.5% に決め打つというものがありますが……標準的なUCBの実装では、これを定数にせず、行った run の回数の関数として徐々に緩めます(i.e.区間を広くします)。こうすると、run の回数が増えるに従い、探索回数が少ない slot を再度探索する効果が期待されます。
UCBはリグレットという値を定義して解析すると、理論的に良い性質を持つらしいです。が、良く知らないです。
実験結果
実験設定は真面目に書く必要が……あるかもと思ったのですが……めんどくさいので適当に省きます。 標準的なslotでは0/1の2値だそうですが、今回、平均=[0, 100],分散=10の正規分布としました.slotの台数は10台です。
適当なslot設定に対し、
- epsilon-greedy(epsilonを0.1 -> 0.001に線形に減少させる)
- UCB-like(信頼区間を99.5%に固定)
- UCB
の振る舞いを比較します。ランダムなslotの初期化を100回試し、その100回の試行での平均的な振る舞いを見ます。各試行におけるrunの回数は50, 500, 3000, 10000で試します。これは、十分な探索すらできない —> 探索、活用に十分な時間がある 時の振る舞いをみるためです。
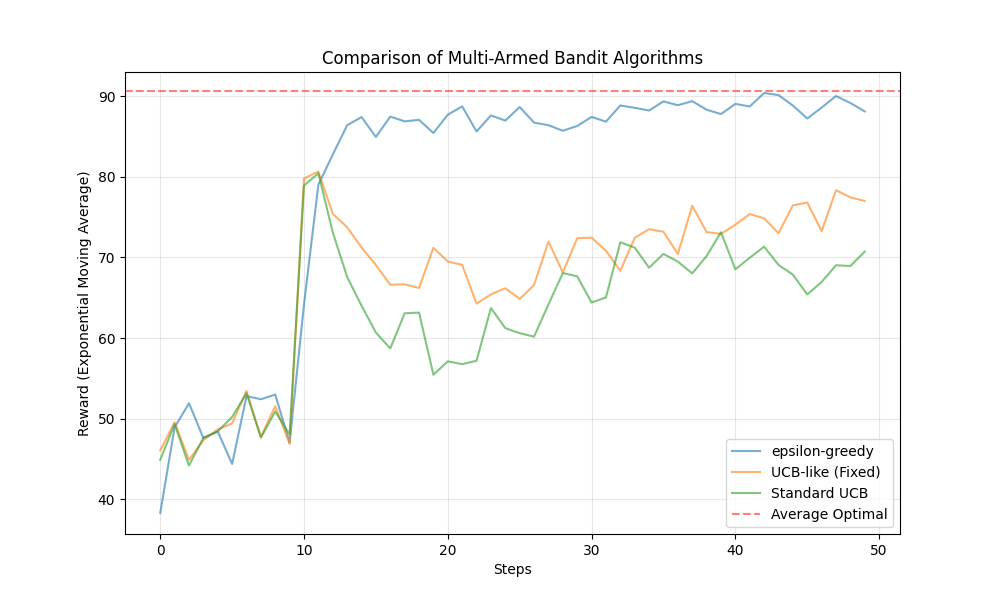
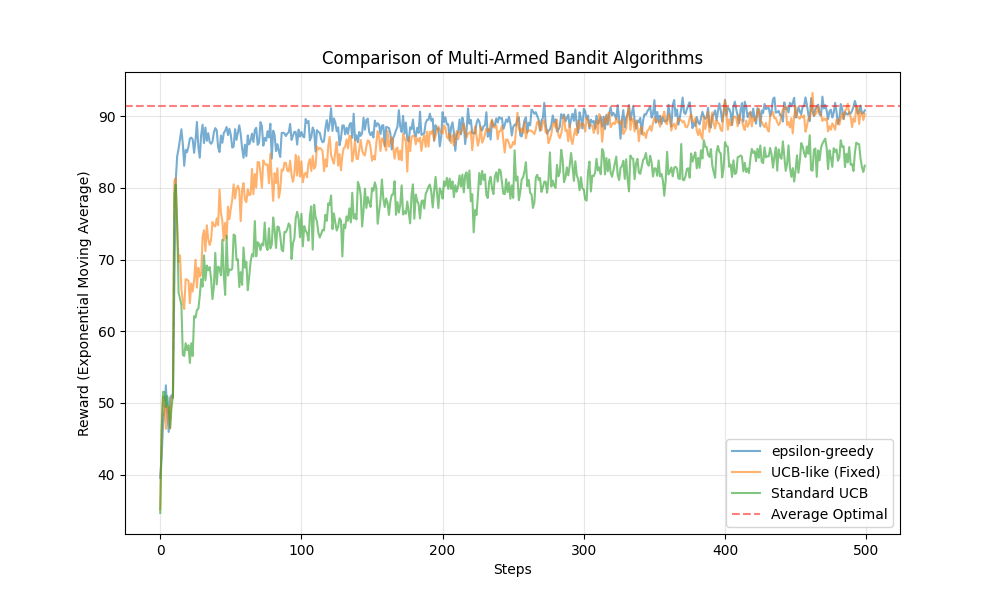
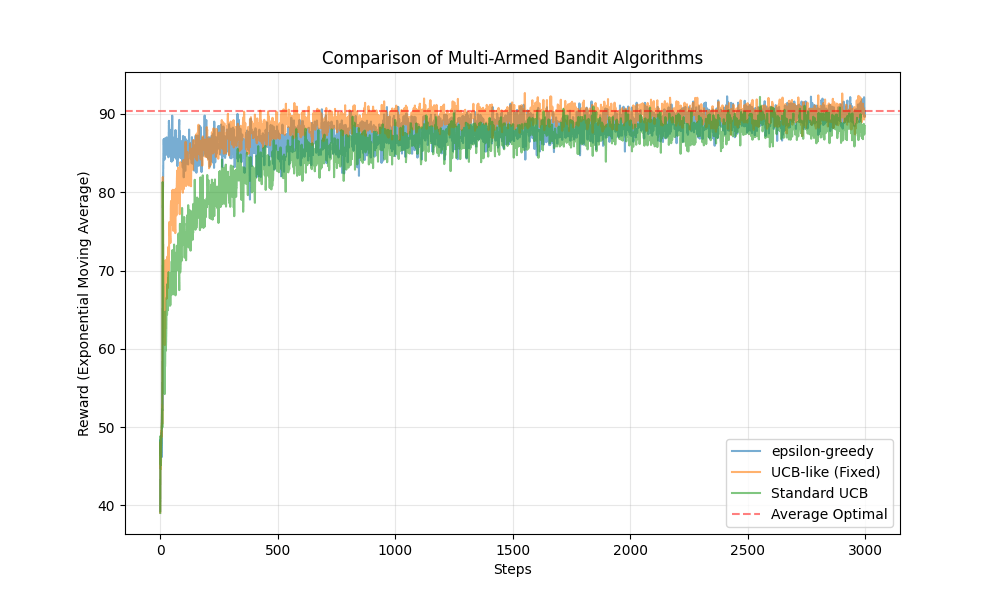
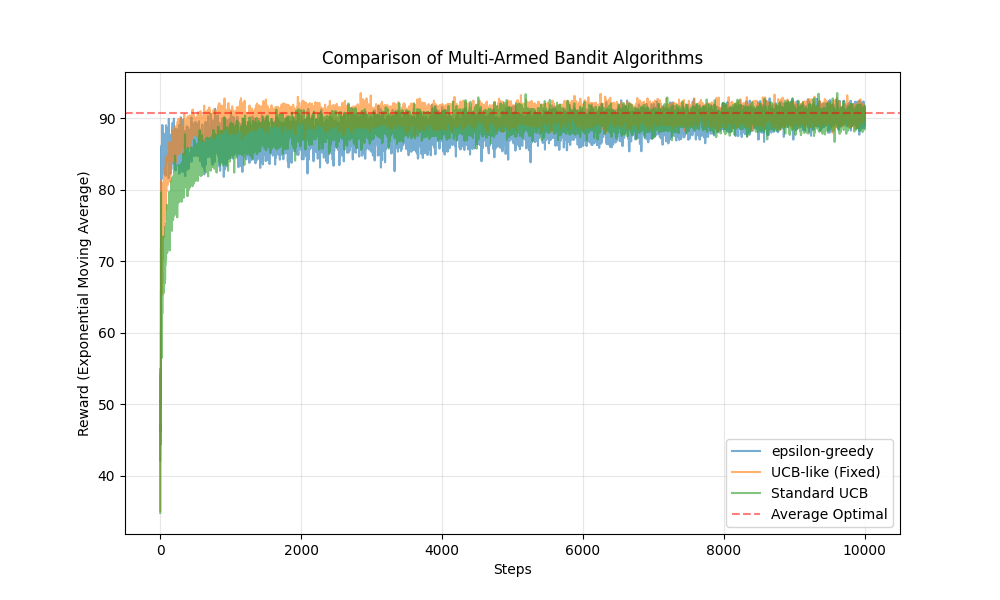
総じてepsilon-greedyの性能が良いです。特に立ち上がりが良いです。しかし、t=10000の時収束の早さで劣っており、線形にepsilonを下げていくことの弊害が出ています。
終わりに
面白い問題設定だと思います。
実験結果的には……ある程度予想できたことではありますが……単純なアルゴリズムで十分な性能が出ていると思います。
理論解析までちゃんとやるとUCBの素晴らしさがわかるのかも知れませんが。今はモチベーションが無いので、悪しからず。
UCBについて、ロバスト性が魅力かなと思います。一方で、logやsqrtが入るため、定数倍的な意味で計算が重いものと思われます。
少なくとも、どちらか一方が上位互換である、という関係ではなさそうです。
今回の設定では、少なくとも各slotについて一度は試せるような数値でした。これはいろいろなゲームでも当てはまります(その盤面で取れる可能な手が十分少なければ良いです)。が、当然当てはまらないゲームもあり……そういった場合、そもそもbandit problemの枠組みで考えるのが厳しい気もしますが。
では。